
O que é e o que causa LAG no RagnaTales - Parte 01

Bom, hora de parar de enrolar e finalmente escrever o post técnico sobre o que é e o que causa lag aqui no Tales.
Vou dividir essa série em três episódios, nos quais vamos discutir, em ordem, sobre:
- Lag de rede.
- Lag gráfico.
- Lag do emulador.
Espero que essa série traga a tão necessária transparência sobre esse assunto e ajude os jogadores a entenderem os esforços da administração no investimento pela qualidade e estabilidade do servidor.
Entendendo o que é Lag de Rede:
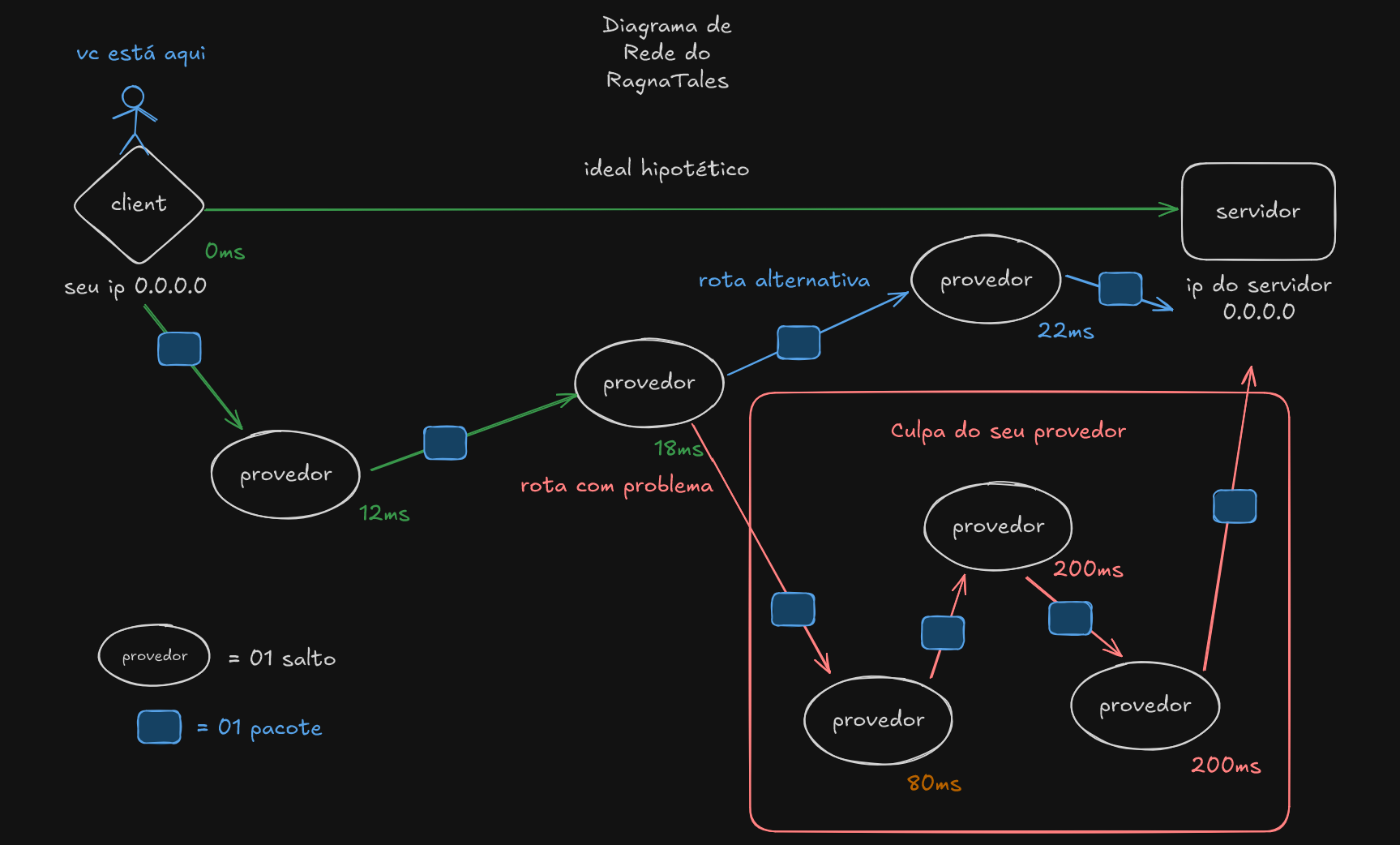
Esse tipo de lag geralmente afeta grandes grupos de jogadores ao mesmo tempo, quando ocorre do lado das grandes operadoras, ou todos os jogadores quando ocorre do lado do servidor.
Para entender um pouco mais sobre isso, preparamos um diagrama e uma explicação detalhada de como o protocolo de rede que usamos no servidor funciona:
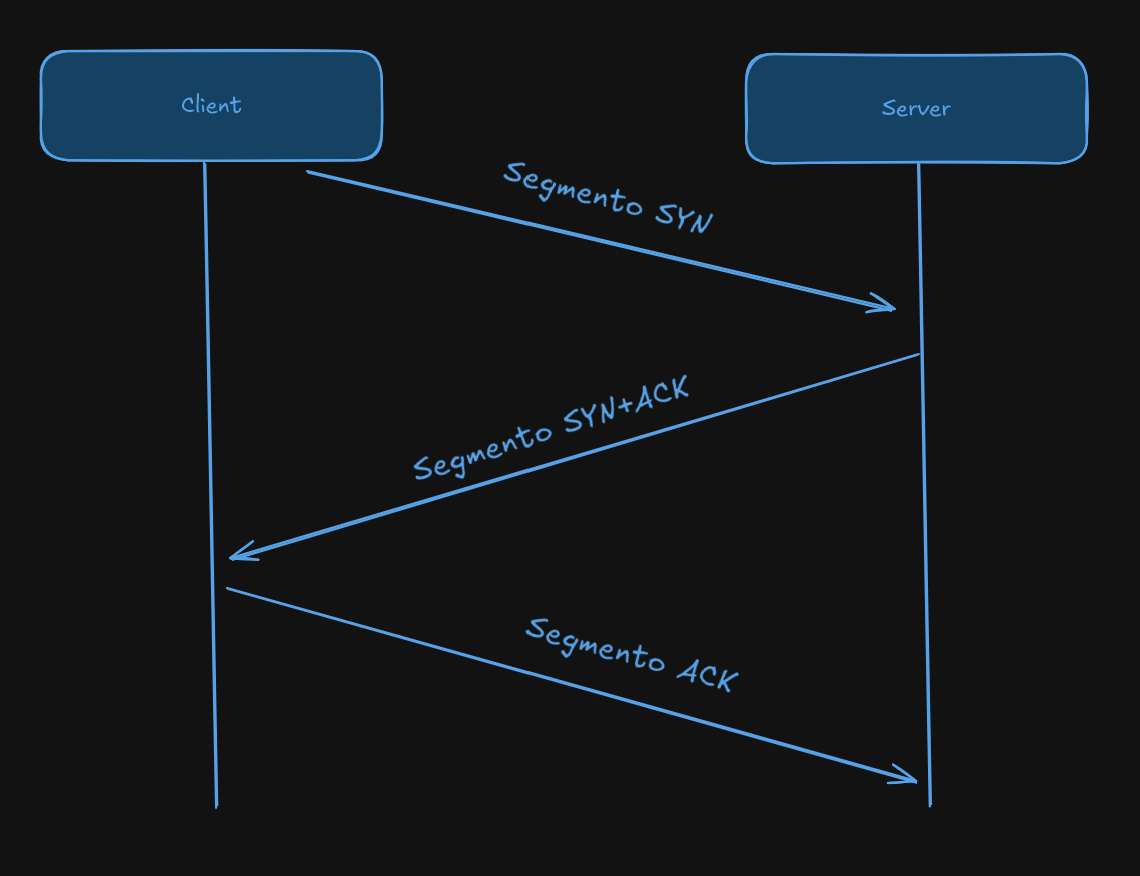
O nosso emulador utiliza o Protocolo de Controle de Transmissão (TCP), que funciona como um serviço de correio ultraconfiável para dados na internet, garantindo que tudo chegue ao destino na ordem correta e sem perdas. Diferentemente de protocolos não garantidos (como o UDP), o TCP estabelece a comunicação através de um "Three-Way Handshake" (aperto de mão em três vias):
- O cliente envia um SYN (Sincronizar).
- O servidor responde com um SYN-ACK (Sincronizar-Reconhecer).
- O cliente finaliza com um ACK (Reconhecer).
Uma vez estabelecida a conexão, os dados são divididos em segmentos menores, cada um com um número de sequência. O receptor confirma o recebimento bem-sucedido de cada segmento enviando um ACK (Reconhecimento). Caso um segmento seja perdido ou chegue fora de ordem, o emissor o retransmite até receber a confirmação. Este ciclo contínuo de checagem e retransmissão é o que confere ao TCP a robustez necessária para serviços críticos como web browsing (HTTP) e e-mail, priorizando a garantia de entrega total e ordenada em detrimento de uma velocidade bruta.
Algoritmos de Controle de Congestão: BBR e FQ
Além da confiabilidade da entrega, a eficiência do TCP é crucial, especialmente ao lidar com grandes volumes de pacotes e congestionamento de rede. Para isso, são empregados algoritmos modernos de controle de congestão, como o BBR (Bottleneck Bandwidth and Round-trip propagation time), frequentemente utilizado em conjunto com a disciplina de enfileiramento FQ (Fair Queue).
BBR (Bottleneck Bandwidth and Round-trip)
O BBR é um algoritmo de controle de congestão que se afasta do método tradicional de detecção de perdas para inferir congestionamento. Em vez disso, ele foca em identificar dois parâmetros cruciais da rede: a Largura de Banda do Gargalo (Bottleneck Bandwidth) e o Tempo de Propagação de Ida e Volta (Round-trip Propagation Time - RTT mínimo).
Ao medir ativamente esses valores, o BBR consegue determinar o ponto ideal de envio de dados e aplica o que é chamado de "pacing" (cadência) no processamento dos pacotes. O pacing consiste em enviar os pacotes em um ritmo constante, calculado para preencher o gargalo da rede sem, contudo, causar filas excessivas (queuing) nos buffers dos roteadores. Isso ajuda a evitar o bufferbloat, reduz a latência e aumenta o throughput efetivo, resultando em uma experiência de navegação mais rápida e consistente.
FQ (Fair Queue)
O FQ, ou Enfileiramento Justo, é uma disciplina de queuing que opera na camada de agendamento de pacotes da rede. Sua função é garantir que, quando um servidor ou roteador precisar lidar com múltiplos fluxos de dados (várias conexões TCP) simultaneamente, cada fluxo receba uma porção justa e equitativa da largura de banda disponível.
O FQ faz isso ao organizar os pacotes em filas separadas (uma para cada fluxo) e, em seguida, ciclicamente, retira pacotes de cada fila de forma round-robin. Isso impede que um único fluxo de dados grande e agressivo (como um download pesado) monopolize a capacidade de transmissão, permitindo que outros fluxos menores e mais sensíveis à latência (como VoIP ou jogos online) mantenham um desempenho aceitável. A combinação do BBR (que determina a taxa de envio ideal) com o FQ (que garante a justiça entre os fluxos) otimiza significativamente o desempenho e a estabilidade da rede.
Espero que minha explicação não tenha ficado maçante, mas ela é crucial para entendermos como o Lag de rede acontece e como ele é resolvido.
Onde as coisas começam a dar errado:
O IX.br é a maior rede de Pontos de Troca de Tráfego (PTTs) do mundo, uma iniciativa do CGI.br e NIC.br que conecta diretamente provedores e redes no Brasil. Seu objetivo principal é reduzir custos, latência e melhorar a qualidade da internet ao permitir a troca de dados localmente, sem depender tanto de redes internacionais, sendo essencial para a infraestrutura digital nacional.
Apesar disso, a centralização do peering no IX.br de São Paulo (IX-SP), com operadoras optando por se conectar majoritariamente ou exclusivamente lá, mesmo tendo Pontos de Troca de Tráfego (IX) regionais mais próximos, cria um problema grave de concentração de tráfego e fragilidade da rede nacional. Cerca de 60% do tráfego agregado do IX.br passa por São Paulo, o que contraria o princípio de distribuição e resiliência da internet, projetada para que o tráfego local permaneça local, reduzindo a latência e o custo.
O Risco da Indisponibilidade
Caso ocorra uma falha grave em um dos Points of Interconnection (PIX) do IX-SP, como um incêndio (como o ocorrido em um datacenter em 2025) ou um rompimento de fibra de grandes proporções (como o mencionado no Cirion/Elea ou Equinix, que são locais de PIX), o impacto é amplificado, podendo causar instabilidade ou indisponibilidade de acesso a grandes serviços e conteúdos para milhões de usuários em todo o Brasil.
Essa dependência excessiva compromete a continuidade do negócio e a experiência do usuário final, já que as rotas alternativas, muitas vezes distantes, levam a uma convergência mais lenta e latência elevada, até que o tráfego seja reencaminhado.
E é isso que geralmente acontece nas vezes em que todos os jogadores estão sentindo lag ao mesmo tempo.
DDOS, o terror dos jogadores:
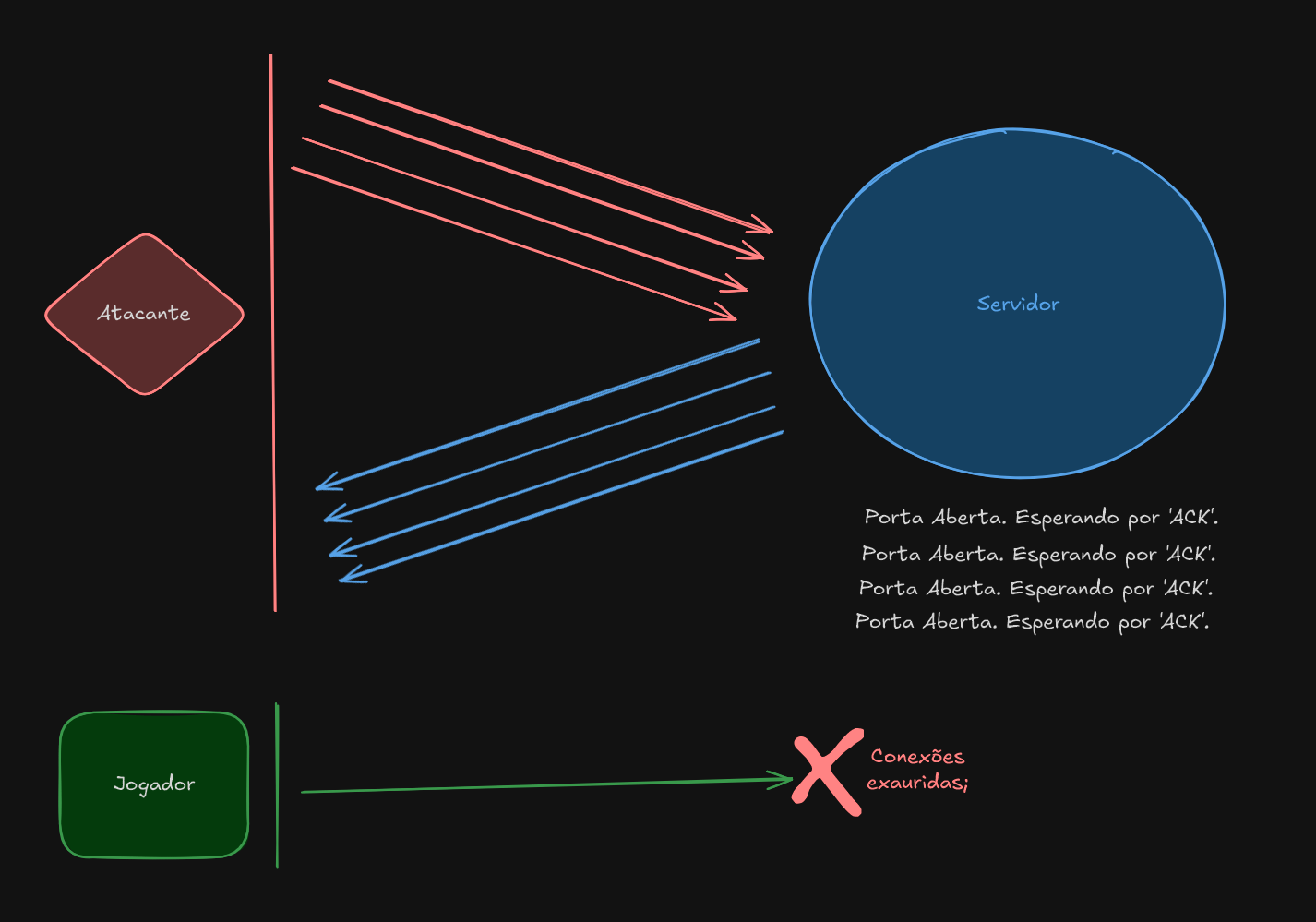
Um dos métodos mais comuns utilizados por indivíduos com o objetivo de causar lentidão (lag) ou indisponibilidade total do servidor é o Distributed Denial of Service (DDoS). Este tipo de ataque não visa roubar dados, mas sim sobrecarregar o sistema alvo, seja a rede, os recursos de CPU/Memória, ou a capacidade de conexão (bandwidth), com um volume massivo de requisições ou tráfego de múltiplas fontes simultâneas. O ataque é distribuído porque utiliza uma rede de computadores comprometidos, frequentemente chamada de botnet, para inundar o alvo, tornando a mitigação mais difícil. O objetivo final é negar o serviço aos usuários legítimos.
Estratégias de Mitigação: Anycast, Proxies Reversos e Firewalls
A defesa contra ataques DDoS exige uma abordagem em camadas, onde o foco principal é dispersar o tráfego de ataque antes que ele atinja o servidor de origem (origin server) e filtrar as requisições maliciosas. Aqui vão algumas delas que utilizamos no Tales, sem entrar em muitos detalhes para não comprometer nossos esforços de segurança de rede:
1. Proxies Reversos Anycast (Anycast Reverse Proxies)
O uso de uma arquitetura Anycast é uma das defesas mais eficazes contra ataques DDoS de grande volume (camada 3/4).
- Princípio do Anycast: Em vez de atribuir um endereço IP a um único servidor (Unicast), o Anycast atribui o mesmo endereço IP a múltiplos servidores distribuídos geograficamente em vários data centers (Pontos de Presença - PoPs) ao redor do mundo.
- Mitigação de DDoS: Quando um ataque DDoS massivo é lançado, o tráfego é roteado automaticamente para o PoP mais próximo do atacante (ou da botnet). O volume total do ataque é então dividido e disperso pela infraestrutura global do provedor Anycast (como Cloudflare, Akamai, etc.). Isso permite que o tráfego seja "absorvido" por uma vasta rede, diluindo o impacto em qualquer servidor individual .
- Proxy Reverso: Atuando como um Proxy Reverso, esses PoPs inspecionam o tráfego. Eles recebem as requisições dos clientes (incluindo as de ataque) e as repassam para o servidor de origem somente se forem consideradas legítimas, adicionando uma camada de proteção.
2. Firewalls Robustos (WAF e Network Firewalls)
Enquanto o Anycast ajuda a lidar com o volume, os firewalls são essenciais para a filtragem do conteúdo (ataques de camada 7) e para a inspeção de protocolos (ataques de camada 3/4).
- Web Application Firewalls (WAF): Os WAFs são críticos para mitigar ataques na camada de aplicação (HTTP/HTTPS). Eles inspecionam o conteúdo das requisições e podem detectar padrões de ataques como SQL Injection, Cross-Site Scripting (XSS) e, crucialmente para DDoS, ataques de inundação de requisições (HTTP Flood). O WAF pode impor limites de taxa (rate limiting) por endereço IP e utilizar desafios (challenges) baseados em JavaScript (como o CAPTCHA) para distinguir robôs maliciosos de usuários legítimos, antes que a requisição chegue ao servidor de origem.
- Network Firewalls e ACLs: Em camadas mais baixas (camadas 3 e 4), firewalls de rede e Listas de Controle de Acesso (Access Control Lists - ACLs) podem ser configurados para bloquear tráfego com características de ataque conhecidas, como pacotes malformados, IP Spoofing e certos tipos de ataques de inundação de protocolo (e.g., SYN Flood ou UDP Flood).
A combinação estratégica da dispersão geográfica do tráfego via Anycast e Proxy Reverso com a inspeção profunda de pacotes realizada por WAFs e firewalls de rede oferece a defesa mais completa contra a vasta gama de ataques DDoS que o servidor pode enfrentar.
Mas essa defesa não é impenetrável, às vezes, dependendo do tamanho do ataque, ele vai vazar e acabar afetando a experiência dos jogadores independente dos nossos esforços para proteger o servidor.
Isso é esperado e, quando acontece, agimos rápido para mitigar o impacto.
O que são e para que servem os Proxies?
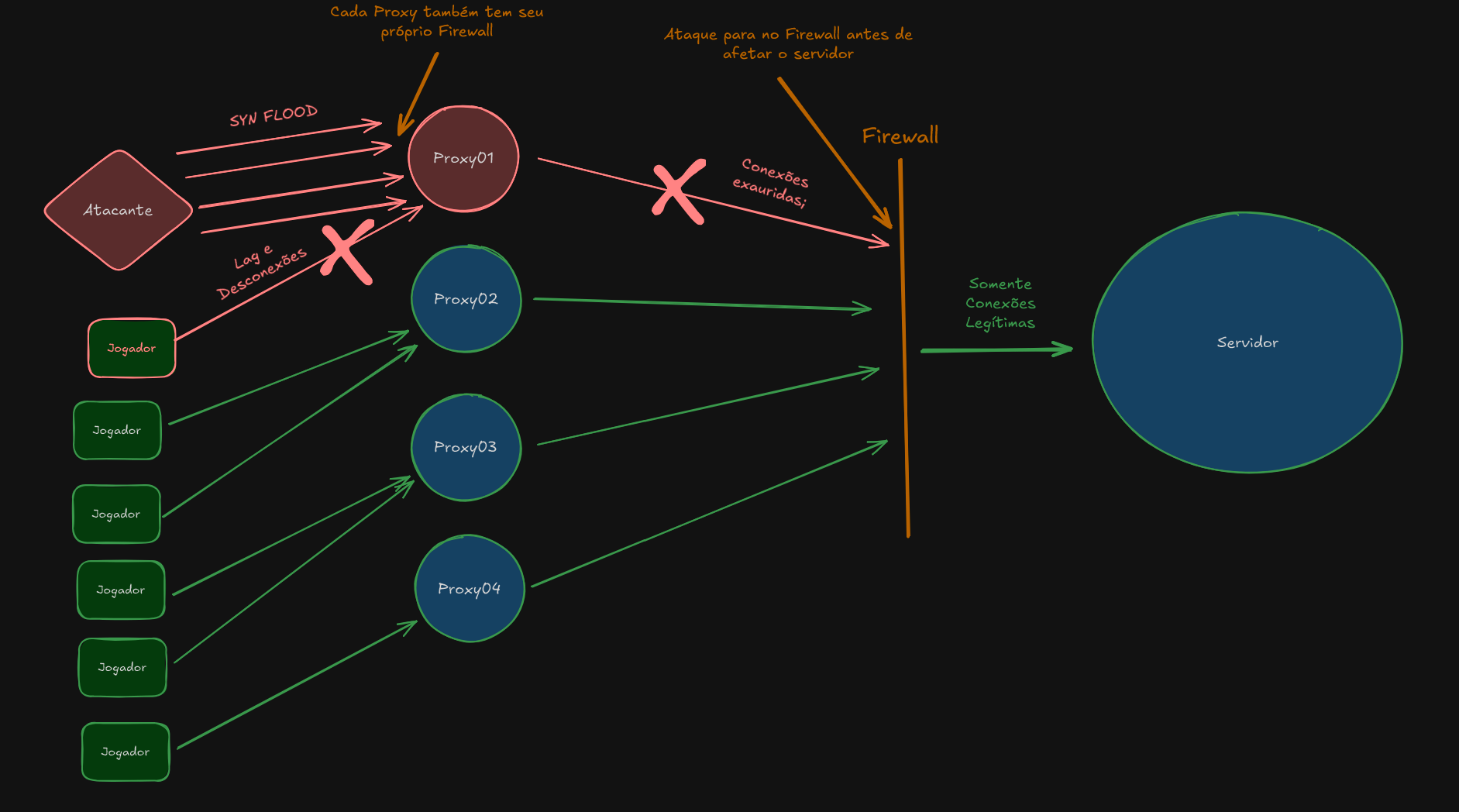
A Função Estratégica dos Nossos Proxies de Rede
Os proxies são a nossa primeira linha de defesa e desempenham um papel vital na segurança e resiliência do nosso serviço. O papel principal deles é proteger o servidor que hospeda o emulador do jogo de várias ameaças.
Em termos práticos, eles servem para:
- Proteção contra Ataques: Blindar o servidor principal contra ataques diretos, como floods de conexões fantasmas e tentativas de DDoS de menor volume.
- Ocultação do IP: Proteger o endereço IP real do servidor de jogo. Se o IP real for exposto, ele se torna um alvo direto e a proteção dos proxies é contornada.
O Papel do "Proxy Descartável"
Nós projetamos os proxies para serem descartáveis em caso de ataque. Embora possuam seus próprios firewalls, eles são máquinas com recursos menos potentes que o servidor de jogo.
Quando um proxy está sob ataque pesado ou sobrecarregado, ele é feito para cair. É nesse momento que você recebe a mensagem dentro do jogo: "Por favor, altere o proxy."
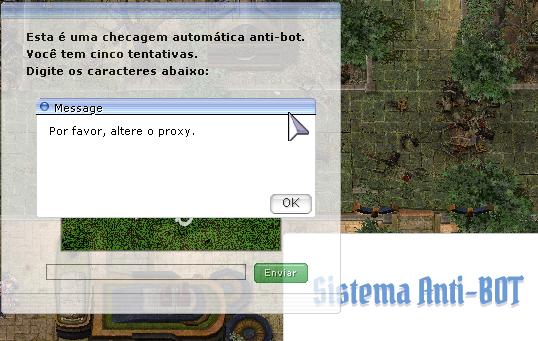
Essa é uma manobra de proteção. Ao cair, o proxy interrompe completamente a transmissão de qualquer tipo de tráfego (incluindo o malicioso) para o servidor principal. Quando ele retorna à operação, geralmente, o tráfego de ataque já cessou ou foi absorvido por outro proxy da rede.
E como é que nós monitoramos tudo?
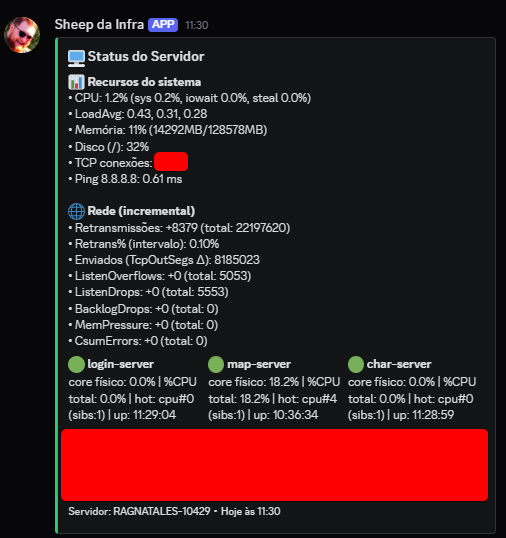
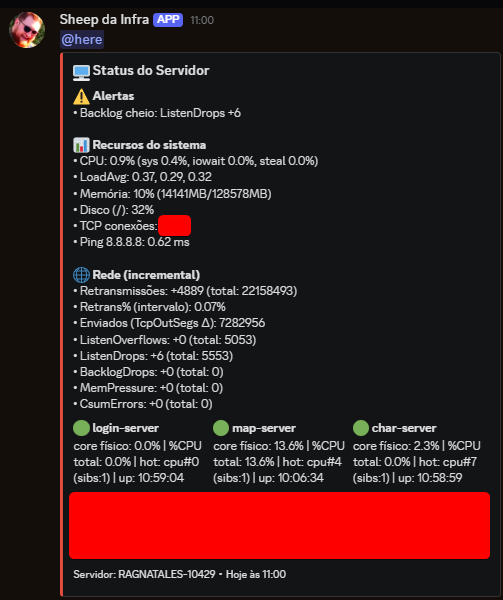
Nossa Suite de Observabilidade: Olhos no Servidor 24/7
Para garantir a estabilidade e a pronta resposta a qualquer falha, mantemos uma visão extremamente completa e em tempo real do que está acontecendo com o servidor e toda a infraestrutura, 24 horas por dia.
Essa visibilidade total nos permite ser imediatamente alertados quando qualquer métrica cruza um limiar de risco ou quando um serviço essencial falha. Isso é crucial para que possamos agir o mais rápido possível para diagnosticar o problema e restaurar os serviços antes que o impacto se generalize.
Ferramentas de Alerta e Monitoramento
Para isso, utilizamos uma combinação robusta de ferramentas:
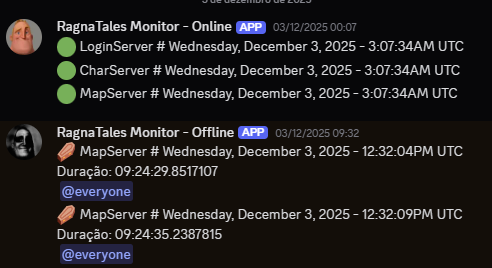
- Bots de Alarme no Discord: Eles funcionam como nossos "alertas de emergência" de primeira linha. Configurados para reportar instantaneamente qualquer anomalia crítica, garantem que a equipe responsável seja notificada imediatamente sobre falhas de conectividade, saturação de disco ou crashes de aplicação, permitindo uma resposta em minutos.
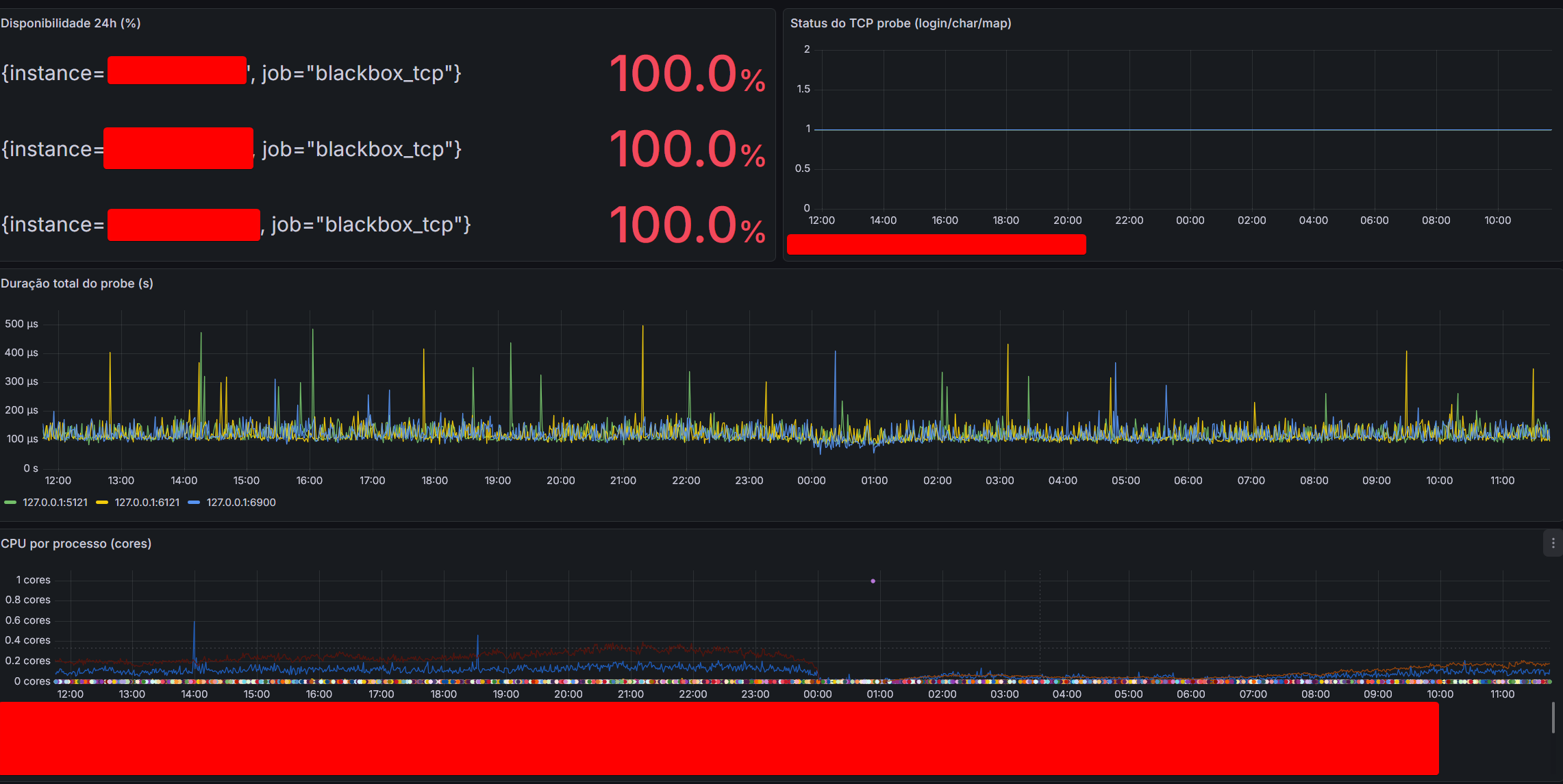
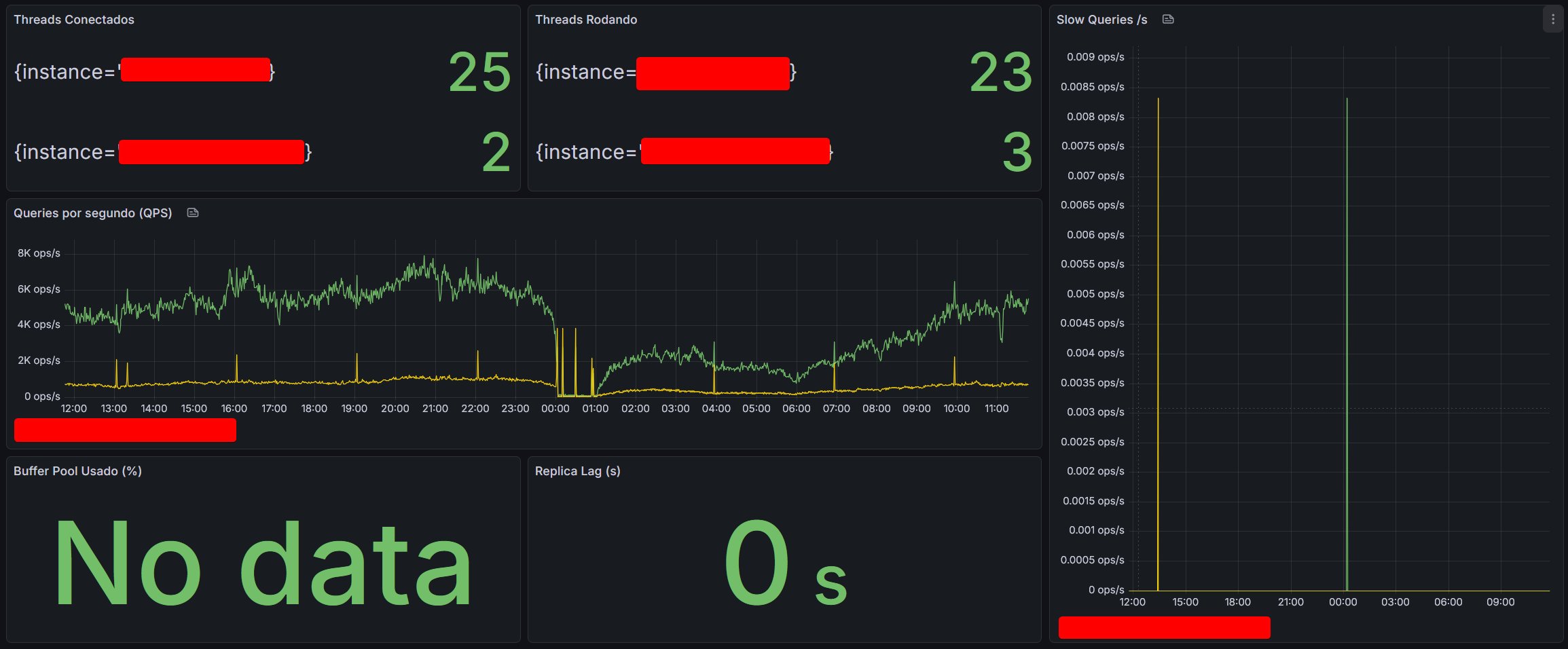
- Prometheus e Grafana: Esta é a espinha dorsal da nossa observabilidade profunda.
- O Prometheus é o sistema que coleta e armazena métricas detalhadas (CPU, memória, latência de rede, desempenho de disco, logs de aplicações, etc.) de toda a nossa infraestrutura.
- O Grafana é o painel onde essas métricas são visualizadas. Ele nos oferece uma visibilidade detalhada e dashboard em tempo real do que está de fato acontecendo dentro das máquinas e aplicações que hosteiam o servidor, permitindo-nos identificar gargalos, picos de tráfego e tendências anômalas antes que se tornem problemas sérios.
Essa suíte de observabilidade transforma um incidente em apenas um alerta a ser resolvido.
E quando a culpa é do ADM?

Ao longo dos últimos anos, felizmente, foram poucas as vezes em que o lag ou a lentidão na rede foram causados por erros da nossa própria administração. No entanto, é importante sermos transparentes e mencionar os incidentes internos que geraram impacto:
- Roteamento Errado do Anycast: O erro mais notório ocorreu com a configuração do nosso reverse proxy Anycast. Em vez de rotear o jogador para o ponto mais próximo no Brasil, a configuração incorreta estava forçando as conexões a dar uma volta desnecessária por outros países antes de retornar ao nosso servidor aqui. O resultado? Um aumento absurdo na latência (ping alto) que nós mesmos causamos.
- Firewall que Bloqueia Demais: Também tivemos casos onde as regras do nosso firewall foram configuradas de forma agressiva demais, bloqueando o tráfego legítimo dos jogadores. O sistema entendia que a requisição era uma ameaça e a descartava, causando falhas de conexão ou lentidão até a correção.
- APIs que Quebram o Jogo: Às vezes, o problema não é a rede em si, mas uma aplicação essencial que falha. Por exemplo, problemas na API do site podem derrubar serviços importantes como o sistema de votação, que é crucial para que os jogadores consigam entregar quests do Éden. Quando o serviço do site falha, o jogo é afetado.
Na maior parte das vezes em que o problema não foi um dos cenários acima (como ataques DDoS, ou problemas de peering no IX.br), ele esteve na empresa que nos fornece o hosting e a infraestrutura de base para as aplicações e o servidor. Embora esses problemas sejam bastante raros, eles podem acontecer e exigem ação imediata.
Fazemos questão de agradecer ao PZ e à equipe da Neep por estarem sempre de prontidão quando um incidente de rede ocorre. A ajuda deles é fundamental para o diagnóstico rápido e a resolução eficiente de qualquer gargalo que possa afetar a experiência de vocês.
A Neep foi e ainda é a melhor empresa de hosting com a qual já lidamos, e olha que passamos por muitas! :)
Com isso concluímos aqui a Parte 1, espero que todos tenham curtido e entendido como as coisas funcionam por trás das cortinas no servidor. Vejo vocês em breve na Parte 2 dessa série, onde iremos falar sobre o temido Lag Gráfico!
Até mais!



